
Word Vectors
어떤 문장이 주어졌을때, 문장의 어떤 부분이 문장의 의미를 더 중요하게 표현하는지를 어떻게 알 수 있을까?
사람의 언어라는 것은 다양한 의미와 뉘앙스를 가지고 있기 때문에, 언어의 정보를 잘 포함하게 표현하고, 이를 다루는것은 정말 어려운 일이다.
one hot vector
word를 다루는 가장 쉽고 기본적인 방법은 단어를 서로 의존하지 않는 개별의 개체로 생각하는 것이다.
즉, 단어를 one hot vector를 통해서 나타낼 수 있다.
예를 들어서 finite set {coffee, cafe, tea}의 개별 단어를 다음처럼 1-hot vector로 표현한다.

전통적딘 NLP에서 단어를 이와 같은 형태로 표현하여 사용한다.
이렇게 표현하게 되면, 두 단어 사이의 L1, L2 distance등의 다른 similarity를 계산할때 항상 0이 나오게 된다.
하지만 실제로 우리가 사용하는 단어들은 그 사이의 연관성을 어느정도 가지게 되는것이 당연하고, 연관성의 정도또한 서로 다르다.
따라서 단어를 independant word vector로 생각하는 one hot vector보다 더 나은 표현방식이 필요하다.
종합하여 one hot vector는 다음과 같은 문제가 있다.
1. sparsity 문제: one hot vector의 sparsity problem. 오직 한개의 element만 1이고, 나머지는 0이다.
2. scalability 문제: voca size가 증가하면, 벡터의 dim또한 linearly 증가함
3. curse of dimensionality 문제: high dimensional data는 computational complexity, overfitting을 일으킴
4. OOV 문제: vector로 표현되지 않은 새로운 단어는 UNK로 함께 묶어야 하는 문제가 발생함
5. Fixed Vocab 문제: 새로운 단어를 추가하는데에 매우 큰 비용 발생
5. Limited information문제: word간의 관계를 알 수 없다
문제가 정말 많지만, 제일 큰 문제는 limited information 문제이다. 이걸 해결하기 위해 등장한게 word2vec 이다.
+WordNet
WordNet은 프린스턴대학에서 단어를 syno/antonyms, hypo/hypernyms, + 다른 단어와의 관계등을 미리 정의하여 제공하는 언어 데이터베이스다.
따라서 미리 정의해둔 언어, 단어에만 사용할 수 있고, 사람이 annotation한 것 이므로 주관적인 판단이 개입된다는 점이 있다.
추가로 새로운 단어와 뜻을 계속해서 추가하고 수정해야하는데, 이에는 비용이 너무 많이 든다는 문제가 있다.
다른 관점에서는, 단어 임베딩에 효율적이지 못한 구조를 가지고 있기 때문이다. 만약 단어에 대한 모든 정보를 포함하고 싶다면, 개별 단어들은 매우 높은 dimension을 가지게 된다.(neural model들에서 좋은 성능을 보이지 않는 구조...즉, tradeoff발생)
Distributional sementics (Word2Vec)
기존의 방법론의 한계점은 크게 두가지로 생각해볼 수 있다.
- sparsity 문제
- semantic meanings of the words 문제
이 두가지의 문제를 해결하기 위해서 단어의 의미를 단어가 쓰민 문맥을 통해 이해하려는 접근법이 나왔다. 한국어로는 분포 의미론이라고 한다.
Distributional sementics의 아이디어는 다음과 같다.
A word's meaning is gien by the words that frequently appear close-by
즉, 단어의 의미는 그 단어가 주로 어떤 단어와 함꼐 나타나는지에 따라서 결정된다.
이런 접근법 하에서 구글에서는 단어를 고정된 크기의 벡터로 표현하는 프레임워크인 Word2Vec를 제시했다.
Word2Vec
Word2Vec 모델은 probabillistic mode이고, 고정된 vacabulary에서 단어를 vocabulary size보다 작은 low dimension의 벡터로 표현한다. (주로 window size로 2~4 word를 사용한다)
즉, one hot vector로 표현되던 것을 작은 크기의 벡터로 표현하는 것이다.
두가지의 모델을 사용한다.
- continuous Bag of Words (CBOW): 주변 단어들로 중간의 단어 예측
- Skip-gram algorithm: 중간 단어로 주변 단어들 예측
skipgram word2vec
중심 단어 c가 주어졌을 때, 주변 단어로 오는 o를 알고싶은것이 skipgram word2vec이다.
skipgram 알고리즘은 다음과 같다.
여기서 u의 경우 word가 context(outside)로 사용되었을 때의 parameter, v읙 경우 word가 center로 사용되었을 때의 parameter이다
알고리즘의 형태가 상당히 익숙한데, softmax와 같은 구조를 가지고 있는것을 알 수 있다.
식을 조금 더 살펴보면
- 분자: dotproduct를 통해서 o와 c의 score를 얻는다.
- 분모: dot product를 통해서 vocabulary의 모든 word와 c의 개별 score를 얻는다
- softmax를 적용한다 - 이를 통해서 probability distribution을 얻게 된다. (중심 단어 c일때 주변단어가 o가 나올 확률을 구한다.)
(softmax : amplifies largest x, but also assigns some prob to smaller x)
여기까지가 확률에 대한 이야기고, 우리가 원하는것은 이게 최적화된 모델을 얻는 것이다.
따라서 Likelihood는 다음과 같다.
- 모든 위치 t에 대해서 window size(m)만큼의 주변 단어들에 대한 확률을 구하여 likelihood를 구한다.
- 여기서 세타는 모델의 모든 파라미터를 말한다. (단어 한개당 두개의(u,v) d-dimension vector의 파라미터가 존재한다)
Likelihood를 통해 얻는 Objective Function(Loss)은 다음과 같다.
Likelihod를 maximize하는것은 Objective function을 minimize하는것과 같다.
위에서 처음 알아본 representation u,v를 적용하면 gradient는 다음과 같이 계산된다
- 마관찰된 단어의 벡터에서 예상되는 모든 context vector의 weighted 평균을 뺀 값이 된다.
- 따라서 학습의 과정에서 모델은 실제 관찰된 단어와 더 비슷한 단어로 예측하는 방향으로 학습된다.
나머지 계산은 다음포스팅에서 더 살펴보자
Word2Vec Problem
다만 이 Word2Vec에는 몇가지 문제가 있다.
- OOV 문제:
- global co-occurrence ignore
- relationship beyond window size
OOV Problem
Word2vec에서는 Top K words만 mapping하고, 다른 단어는 모두 unk 로 분류하여서 representation한다는 문제가 있다.
따라서 훈련중에 드물게 등장했거나, 등장하지 않은 단어에 대해서는 단어의 의미를 파악하지 목한다.
top-k word에 포함되지 않는 단어들은 다음과 같은 유형의 단어들이다.
- compoound words
- derived words
- plurals
- verbs conjugtions
- new words with predictable words
이런 경우에 대해서는 Subword technique 들을 사용한다.
대표적인 모델로 FastText가 있다.
FastText
fasttext는 word2vec의 발전된 모델이다.
단어 전체를 벡터로 바꾸는게 아니라, 단어를 여러 조각의 subword로 나누에서 처리한다. 즉, 단어를 character n-gram 형태로 분리해서 집합으로 표현한다.
이렇게 되면 OOV문제를 조금 해결해볼 수 있고, 문법적 변형도 약간 다룰 수 있게 된다.
Skip-Gram with Negative Sampling (SGNS)
Skipgram의 softmax를 다시 tkfvu 보자.
단어가 주어졌을 때, 분자부분을 계산하는건 사실 비용이 많이 들지 않는다.
문제는 분모인데, 모든 단어들에 대한 score를 구해서 더하는 방식으로 normalize하고 있다.
이 부분에서 computing하는데에 비용이 많이 든다는 문제점이 있다.
즉, 이 알고리즘은 단어와의 관계를 학습하기 위해서 V의 모든 단어를 확인해야 한다. 따라서 단어의 풀이 커지면 그만큼 계산비용도 커지게 된다.
그럼 우리는 이 문제점을 해결하기 위해서 분모부분을 없애버리고 싶어진다.
이 분모부분의 역할은 아래와 같다.
- 확률론적인 관점에서, 분모 부분은 모든 score값의 합이 1이 되도록 normalize하는 역할을 한다. 여기서 exponential 은 개별 score값이 항상 0혹은 양수가 되도록 한다.
- learning의 관점에서, 분모 부분은 관찰되지 않은 단어들에 대한 스코어들을 낮추는 역할을 하게 된다. 즉, 분자는 모델이 o와 c의 유사성을 높이는 방향으로 학습되고, 분모는 나머지 모든 단어들의 유사성을 낮추게 압박하는 역할을 한다.
네거티브 샘플링은 분모를 통해 항상 다른 모든 단어에 대한 score를 낮출 필요가 없다는 점에 착안한다.
다만, 실제의 SGNS의 objective function은 약간 다른점이 존재한다.
핵심 아이디어는 다음과 같다.
Train Binary Logistic Regressing for a true pair & several noise pairs
즉, 실제 단어 쌍괴 몇개의 노이즈 쌍을 대상으로 Binary Logistic Regression을 학습한다.
SGNS 과정
1. 중심단어 C와 주변 단어들을 추출하여 true pair로 사용한다
2. 중심단어 C와 무작위 단어들을 추출하여 negative noise pair로 사용한다.
3. Binary Regression을 통해 true pair와는 가까워지게(1), negative pair(0)와는 멀어지게 학습한다.
논문에서 제시한 Objection Function은 다음과 같다.
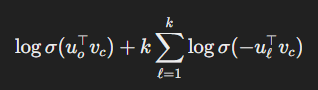
이렇게 되면, 모든 단어에 대해서 스코어를 계산하지 않고, 몇개의 노이즈 샘플과 true pair에 대해서만 학습하기 때문에 계산의 효율성이 높아진다는 장점이 있다!
'🦄AI > NLP' 카테고리의 다른 글
| [NLP] Seq2Seq모델과 Attention 메커니즘 이해 (0) | 2025.04.16 |
|---|