[Machine Learning] Decision Trees
Decision Tree
머신 러닝에서 Decision Tree는 데이터를 분류하거나 예측하는 알고리즘 중 하나이다.
이 방식은 Classification과 Regression에 모두 사용 가능하다
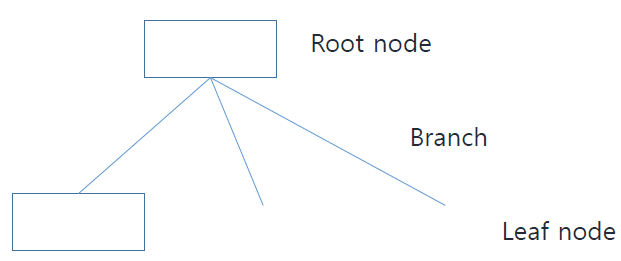
Decision Tree가 어떻게 생겼는지 살펴본다.
Root node와 Leaf node에 해당하는 사각형에는 feature가 들어간다.
Branch의 경우 위의 feature에 대한 내용이 된다.
Classification
먼저, Decision tree를 통해 classification 문제를 어떻게 해결할 수 있는지 알아본다.
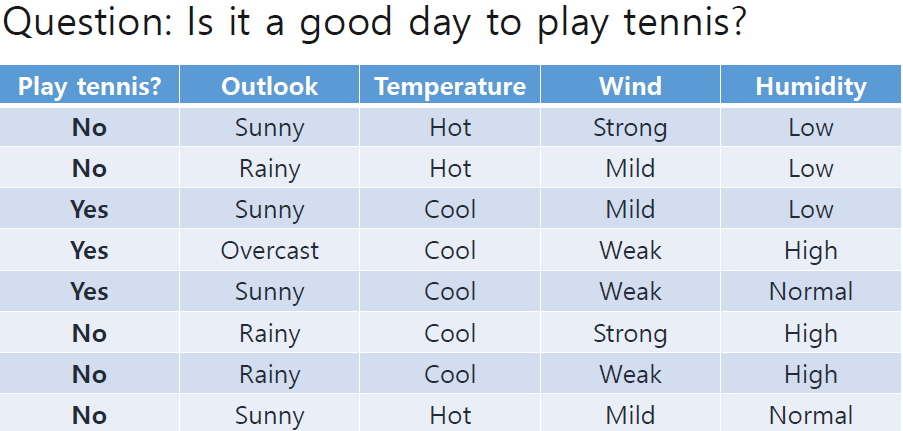
이번 포스팅에서 예시로 드는 data와 classification 문제는 아래와 같다.
Start
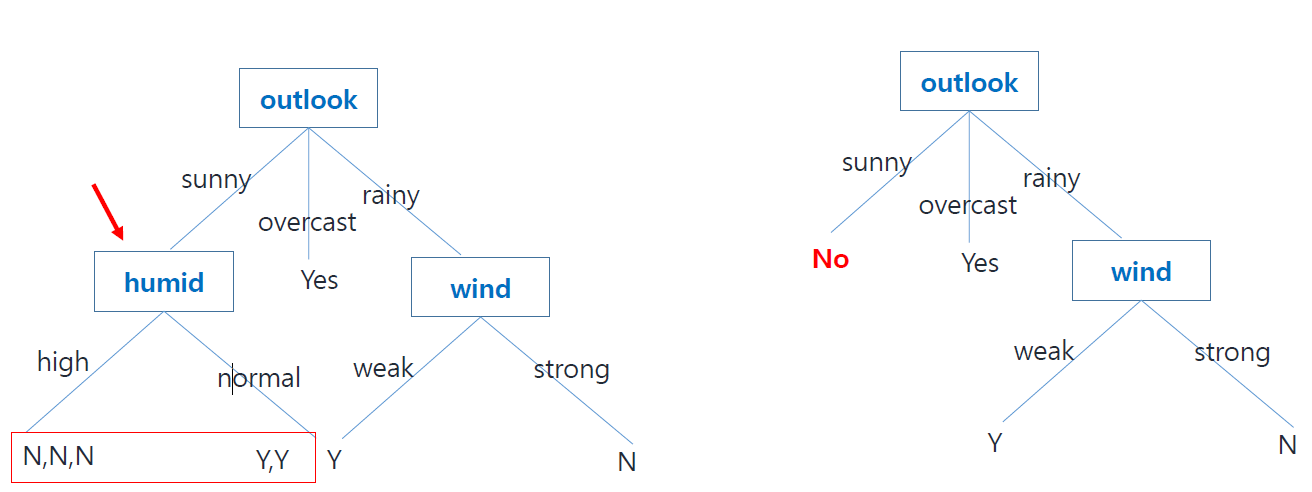
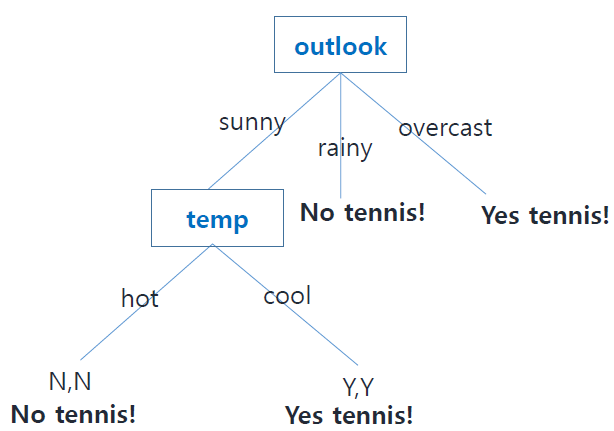
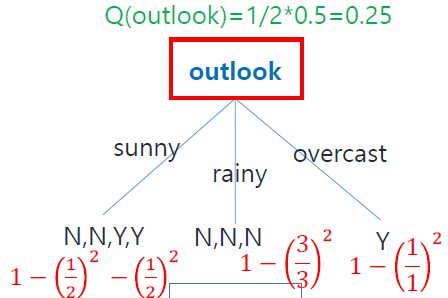
먼저 feature를 outlook으로 하여 decision tree를 작성해보자.
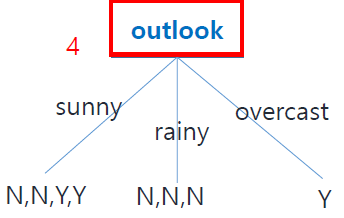
위의 그림과 같이 outlook은 sunny, rainy, overcast가 있고, 해당 feature일 때 각각 label값(N/Y)을 작성할 수 있다.
이렇게 outlook feature를 기준으로 decision tree를 작성한 결과
주어진 데이터셋을 기준으로 rainy와 overcast인 outlook을 가진 경우 label 값을 확정할 수 있다. 즉, rainy일때는 N, overcast일 때는 Y로 label값을 결정할 수 있다.
그러나, sunny인 경우에는 N과 Y가 섞여있는것을 볼 수 있다.
이 경우를 우리는 Impure하다고 할 수 있고, 단순히 outlook만을 노드로 가지는 decision tree는 classification문제를 해결할 수 없음을 알 수 있다.
Homogeneous group
Classification 문제에서 Homogeneous group은 feature에 의해서 나누어진 결과, 하나의 label만 가지는 data 집합을 말한다. 즉, 위의 예시에서는 rainy 일때 {N,N,N}, overcast 일때{Y}를 말한다.
outlook feature를 사용한 decision tree에서 homogeneous group의 memeber 수는 총 4개인 것을 알 수 있다.
Homogeneous group을 확인하는 것은 tree에 사용할 feature를 탐색하는데에 활용할 수 있다.
Expand the Tree
여러 feature를 활용해서 Tree를 확장할 수 있다.
No Homogeneous Member Exists
그럼, 데이터셋의 크기가 커지면서, 어떤 feature를 사용해도 homogeneous group이 생기지 않는 경우는 어떻게 tree를 결정 할까?
이 경우에는 불확실성/ 불순도를 통해 테스트의 품질을 계산하고,이를 바탕으로 어떤 feature를 사용하여 tree를 구성할 지 결정할 수 있다.
Entropy/Information gain
Entropy는 데이터의 불확실성을 나타내는 지표이다. Decision tree에서는 엔트로피를 분할 기준(feature)의 선택에 사용한다.
개별 branch에 대해서 엔트로피 계산을 하고, 이를 통해 tree의 quality를 계산한다.
엔트로피는 다음과 같이 계산한다.
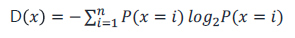
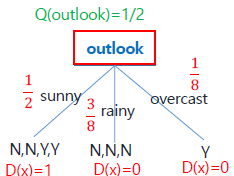
다음과 같이 outlook의 개별 branch에 대한 엔트로피를 구할 수 있다. 엔트로피에 가중치를 부여하여 합한 값을 Quality of Test로 하여 어떤 특성을 트리에 사용할지 결정한다.
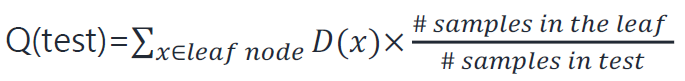
이 값은 entropy의 weighted sum이므로 이 값이 가장 작은 경우의 feature를 선택한다.
Gini Impurity
Gini impurity는 decision tree에서 불순도를 측정하는 지표 중 하나이다. 이는 노드 내에 서로 다른 class의 데이터포인트가 얼마나 섞여있는지를 측정하여 분할 기준을 결정한다. 개별 branch마다 Impurity 값을 계산하고, 이 값들을 이용해 Quality of Test를 계산하여 어떤 특성을 트리에 사용할지 (분할 기준) 선택한다.
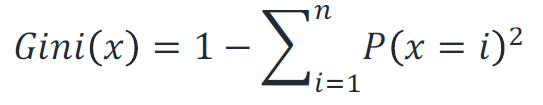
Quality of Test의 경우 동일하게 불순도를 weighted sumation하여 구한다.
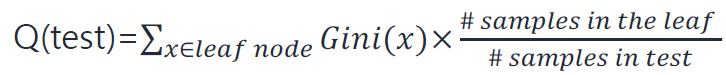
따라서 역시 Quality of Test 값이 가장 작은 경우를 선택하는것이 합리적이다.
Handle Numeric Value
쉽게 보기 위해 위의 dataset을 다시 가져왔다. 여기서 temperature값이 숫자 값이면 decision tree에서는 어떻게 다루어야 할까? 다음과 같이 다룰 수 있다.
1. Sort temperature and calc avg
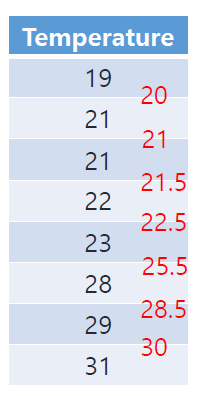
2. 여러 기준 에서 Q를 계산한다. 이때 엔트로피나 지니 불순도 활용. ex(20 이하, 21 이하, 21.5 이하 ...)
3. 가장 작은 Q를 가진 feature 선택한다.
Regression
linear regression을 사용할 수 없을 때, 즉 비선형 관계를 파악하는데에 더 적합한 방식이다.
아래 슬라이드를 통해 regression에서 Decision tree가 어떻게 동작하는지 한눈에 알아볼 수 있다.

문제는 노드를 선택하는데에 있다.
어떤 기준으로 data 를 split해야할까?
일단 데이터를 split하는 지점은 각 data 사이의 interval이다. 이부분은 주로 interval의 중앙을 말한다.
아래의 값이 최소가 되는 interval을 split point로 정한다.
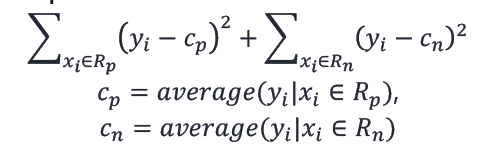
그냥 쉽게 생각하면 interval 왼쪽과 오른쪽 groupe의 제곱오차(Squared error)를 각각 구하여 더한다.
이 값이 가장 작을 때의 interval 중앙을 split point로 정한다.
Overfitting in Decision Tress
Decision tree가 커질수록, 모델은 학습데이터에 너무 맞춰지게 되어 training Data에 대한 accuracy는 증가하지만, test accuracy는 감소하는 overfitting이 생긴다.
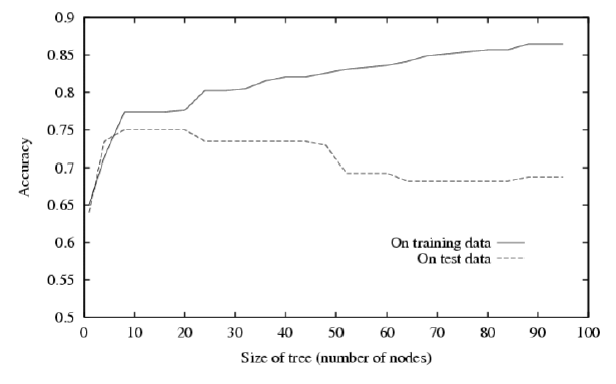
hypothesis h에 대해서 training error보다 test error가 더 높은 경우에 overfitting으로 판단한다.
또한 amount of overfitting은 둘의 차를 말한다.
Avoid overfitting
Pruning(가지치기)을 통해 과적합을 방지한다. 이에는 두가지 방법이 있다.
1. Pre-prining : 트리를 생성할 때 미리 정한 통계적 규칙에 따라서 성장을 조절한다.
2. Post-pruning : 트리를 일다 생성한 후 불필요한 가지를 제거한다(ex,Reduced Error Pruning)
Reduced Error Pruning
다음과 같이 노드를 하나씩 삭제하여 validation accuracy를 계산한다. 만약 validation accuracy가 현저히 낮아지지 않는다면, 노드를 제거한쪽을 선택한다. pruning이 성능을 많이 저하하지 않는다면 계속 반복하여 노드를 줄인다.